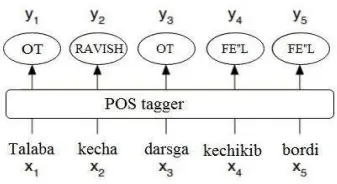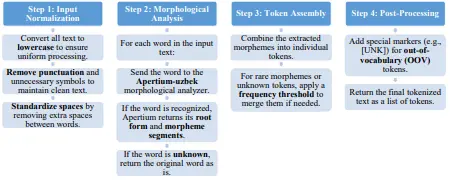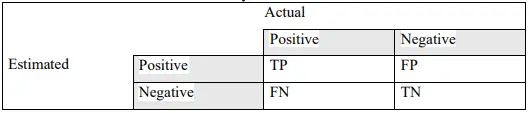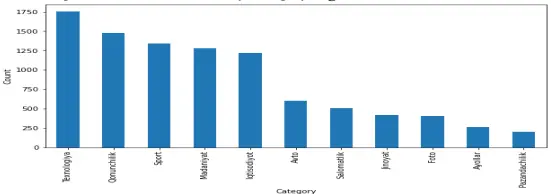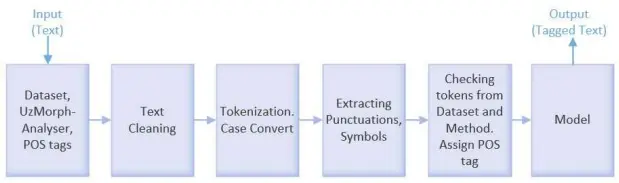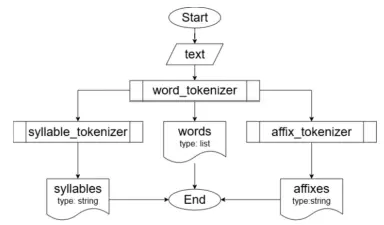
DICTIONARY-BASED TOKENIZATION ALGORITHM FOR UZBEK TEXTS
Tokenization is the process of dividing a text into smaller parts, called tokens. Tokens can be words, punctuation marks, numbers, or other meaningful elements. Tokenization is primarily used in natural language processing (NLP) and is an essential first step for analyzing, understanding, or...
3 November 2025, 22:00